Approach Comparison
How different retrieval strategies explore a knowledge graph
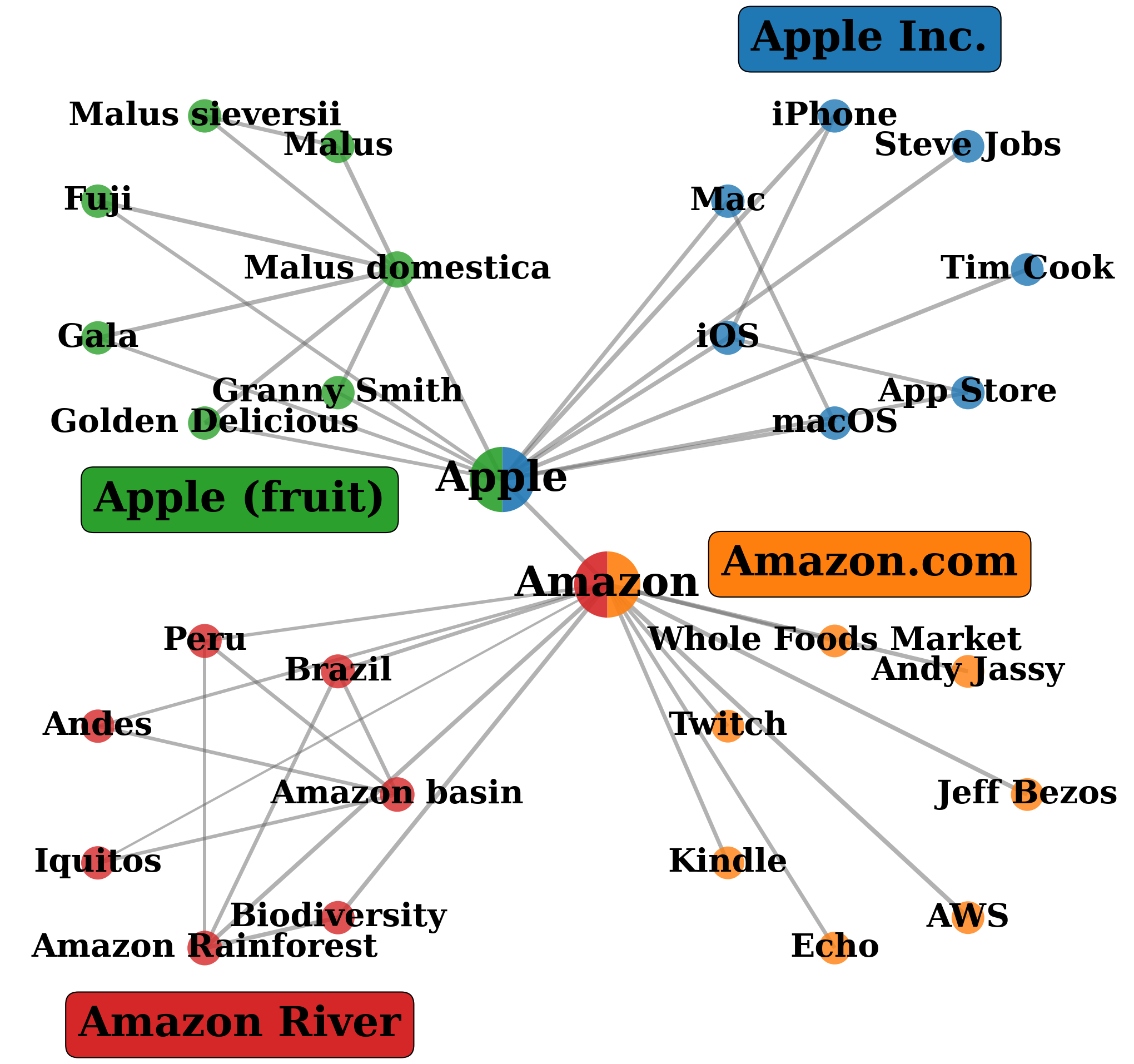
GraphRAG
Community Detection
Community Detection
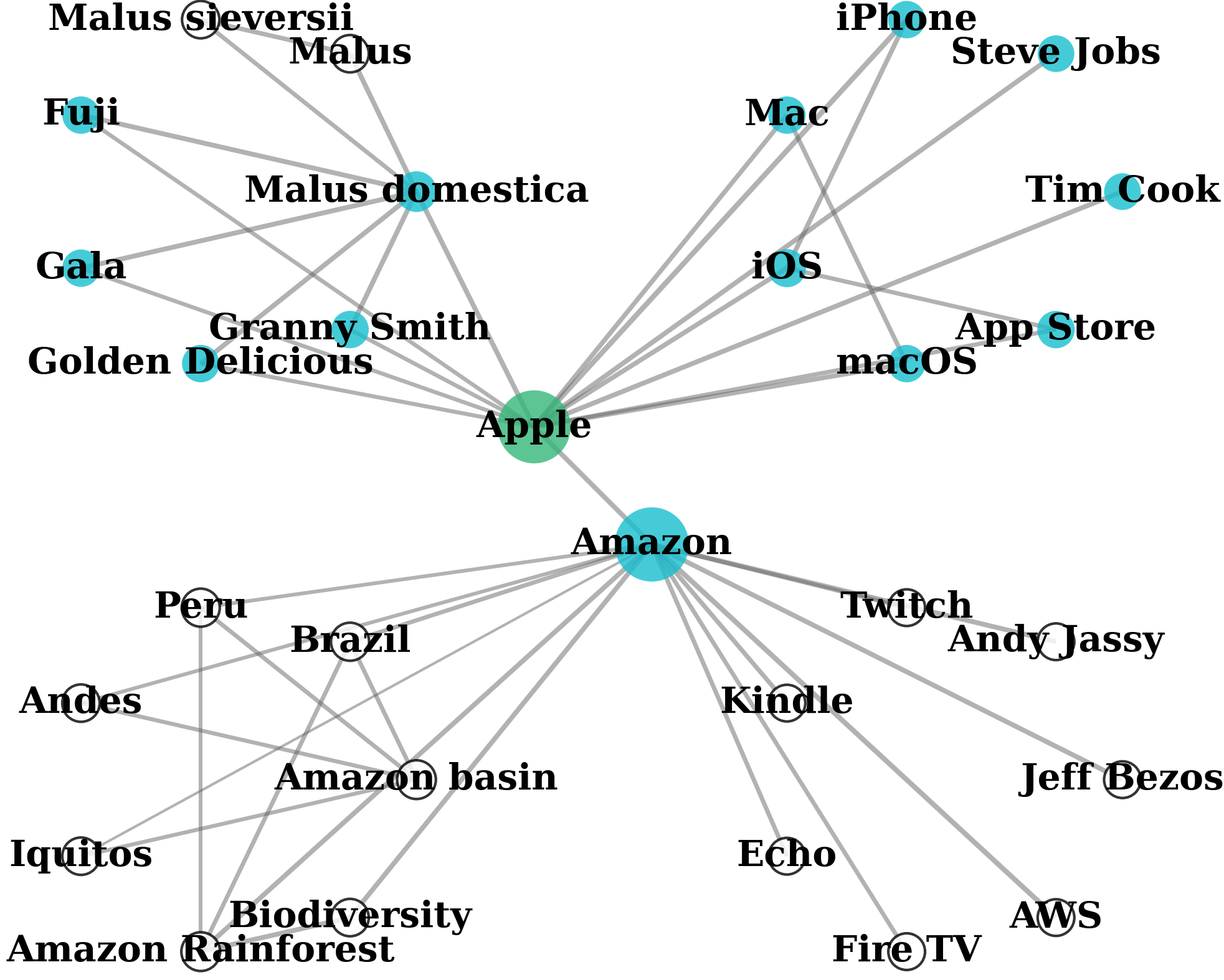
LightRAG
One-Hop Entity-Centric
One-Hop Entity-Centric
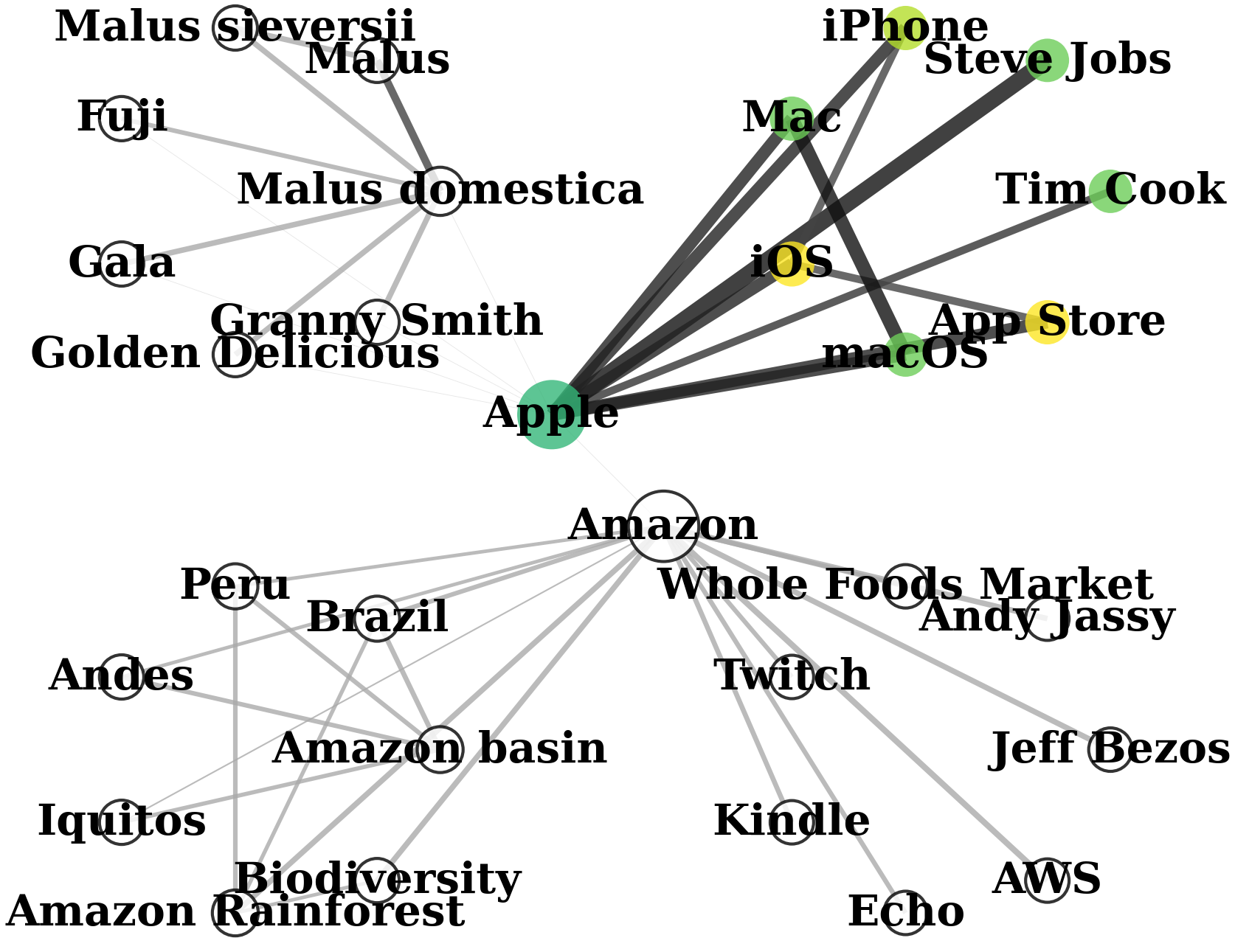
QAFD-RAG (Ours)
Query-Aware Flow Diffusion
Query-Aware Flow Diffusion
Comparison on Wikipedia pages (Apple fruit, Apple Inc., Amazon River, Amazon.com). Query: "Introduce Steve Jobs's products in Apple." GraphRAG retrieves entire communities, mixing relevant nodes with irrelevant ones. LightRAG focuses on 1-hop neighborhoods. QAFD-RAG reweights edges by query meaning, suppressing irrelevant neighborhoods.